
Building a Customer Support Chatbot with RAG, FAISS, and Claude
I recently built a RAG-powered customer support chatbot as part of an AI engineering portfolio project. The chatbot answers support questions (order cancellations, refund tracking, payment methods, etc.) by searching a knowledge base and using Claude to generate grounded responses.
This post walks through the decisions I made while building it, what I learned, and what I’d do differently next time.
The idea
The goal was straightforward: build a chatbot that can answer customer support questions without hallucinating. Instead of relying on the LLM’s general knowledge, the chatbot retrieves relevant information from a knowledge base first, then passes that context to the model. This is the RAG (Retrieval-Augmented Generation) pattern.
I used the Bitext Customer Support dataset from HuggingFace, which has about 27,000 question-answer pairs across 27 support intents like “cancel order,” “track refund,” and “recover password.” The dataset also includes realistic linguistic variation: typos, colloquial phrasing, and different ways customers express the same request.
The architecture
The system has two phases. The offline phase runs once to prepare the knowledge base. The runtime phase handles each user query.
Offline: Load the dataset, group responses by intent, chunk them, embed them with a sentence-transformer model, and store the vectors in a FAISS index.
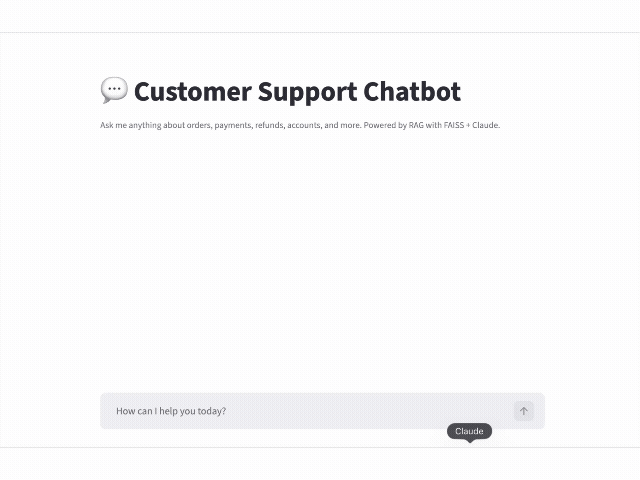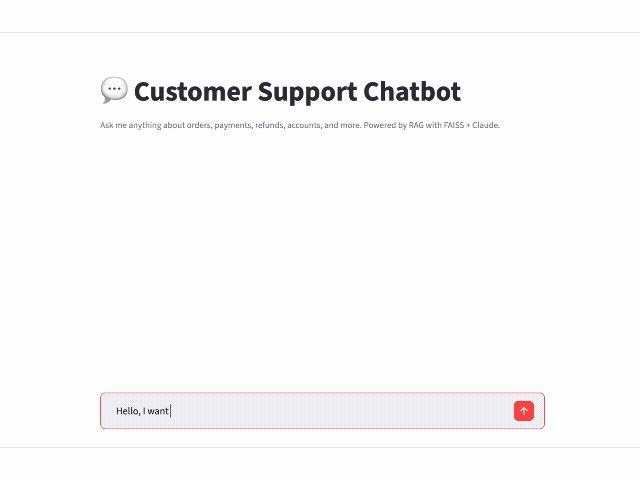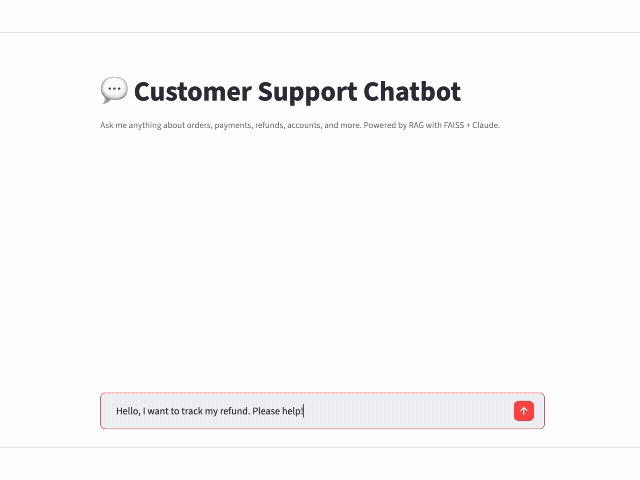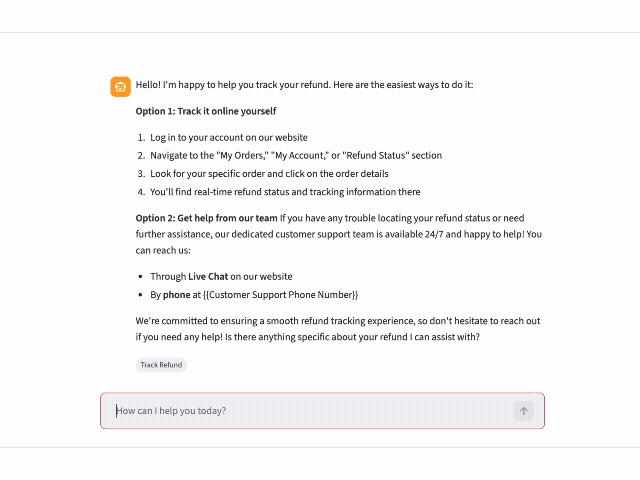
Runtime: Take the user’s question, embed it using the same model, search FAISS for the most similar chunks, format a prompt with the retrieved context, and send it to Claude.
User Question
│
▼
Embed with all-MiniLM-L6-v2
│
▼
FAISS similarity search (top-5)
│
▼
Format prompt with retrieved context
│
▼
Claude generates response
│
▼
Streamlit displays answer + source tags
The part that mattered most: how I structured the data
The most impactful decision in the project wasn’t the LLM or the vector database. It was how I prepared the knowledge base.
My first instinct was to follow the textbook approach: load all 27,000 rows, split them into chunks by character count, embed everything, and let the retriever figure it out. But when I explored the dataset, I noticed something. The 27K rows aren’t 27K unique pieces of information. They’re many different phrasings of the same questions, mapped to the same responses. The “instruction” column has variation (“cancel my order,” “i wanna cancel,” “how do I cancel an order plz”), but the “response” column for a given intent is often identical or near-identical.
If I embedded all 27K rows naively, the vector store would be full of near-duplicate chunks. The retriever would work, but it’d be wasteful and the chunks would be tiny and repetitive.
Instead, I grouped the unique responses by intent. This collapsed 27K rows into 27 coherent knowledge articles, one per support topic. Each article contains the topic name, its category, and all the unique response variations for that intent. These articles then get chunked with RecursiveCharacterTextSplitter, which splits at paragraph and sentence boundaries rather than arbitrary character positions.
The result: the retriever returns chunks that are topically coherent and information-dense rather than fragments of repeated text.
Tech choices and why
FAISS over Pinecone/Weaviate. The dataset produces a few hundred chunks after the intent-grouping and chunking steps. FAISS loads the entire index into memory and searches it in milliseconds. There’s no server to manage, no account to create, and anyone cloning the repo can rebuild the index with python ingest.py. For a dataset this size, a cloud vector database would be overengineering.
Local embeddings (all-MiniLM-L6-v2) over OpenAI’s API. The model is free, runs on CPU, produces 384-dimensional vectors, and is one of the most widely used sentence-transformer models. For a few hundred chunks, there’s no meaningful quality difference compared to a paid embedding API, and removing the external dependency makes the project easier to run.
Claude over GPT. I’m building familiarity with the Anthropic API as part of my career transition into AI engineering, but there’s also a practical reason. Claude’s instruction following is strong, and it reliably stays within the provided context when told to. The system prompt tells it to only use the retrieved context and to say “I don’t know” rather than fabricate an answer, and it actually does.
Direct API calls over LangChain’s RetrievalQA. LangChain is great for text splitting and the retriever abstraction, but I called the Anthropic API directly for the generation step. This makes the retrieval-generation boundary explicit in the code. When something goes wrong, I can see exactly what context was retrieved and what prompt was sent to Claude, rather than debugging through a chain abstraction.
Streamlit for the UI. Quick to build, has native chat components (st.chat_message, st.chat_input), and is familiar to anyone reviewing AI/ML portfolio projects. I added source intent tags below each response so you can see which knowledge base topics the retriever pulled from.
What I’d improve
Conversation memory. Right now each question is independent. If you ask “How do I cancel my order?” and then follow up with “What if it’s already shipped?”, the chatbot doesn’t know what “it” refers to. Adding the conversation history to the prompt would fix this.
Streaming responses. Claude’s API supports streaming, where the response appears token by token. Right now the UI shows a spinner until the full response is ready, which feels sluggish for longer answers.
Better evaluation. I wrote a basic evaluation script that checks whether the correct intent appears in the retrieved sources. This tells me if retrieval is working, but it doesn’t measure whether Claude’s generated answer is actually faithful to the context. A framework like RAGAS could add context relevance and answer faithfulness metrics.
Contextual compression. Sometimes the retrieved chunks contain information that’s relevant to the topic but not to the specific question. LangChain has a ContextualCompressionRetriever that uses an LLM to extract only the parts of each chunk that are relevant to the query. This reduces noise in the prompt but costs an extra API call per retrieval.
What I learned
The biggest takeaway is that RAG quality depends more on data preparation than on which LLM or vector database you use. The choice to group by intent instead of blindly chunking was the single decision that most affected response quality. Everything downstream (retrieval, generation, UI) was relatively straightforward once the knowledge base was well-structured.
The second takeaway is about tooling tradeoffs. It’s easy to reach for the most sophisticated tool (cloud vector DB, paid embeddings, complex chain abstractions), but the right tool is the simplest one that solves the problem. FAISS, a local embedding model, and direct API calls made this project easier to build, debug, and share.
This project is part of a series of AI engineering portfolio projects I’m building. You can find the code on GitHub.
